Evolution of Transformers — Part 1
Introduction
Artificial Intelligence has had quite a journey starting from 1956 when the term was first coined, till today, where it is being used in every field. Deep Learning is slowly surpassing Machine Learning as the preferred method for most of the tasks involving AI, and the models that are leading this evolution are Transformers.
This is going to be a series of 2articles that will go through some ground-breaking Transformer models developed by many researchers over the past 5 years since the development of the first Transformer in 2017.

We’ll briefly go over transformers and 4 transformer architectures that were introduced right after transformers in this part.
Note: Before we begin, let’s see which tasks are performed by which models.
- Encoder-only models: They can be used for tasks where the input should be understood, such as sentiment analysis.
- Decoder-only models: They can be used for tasks where text has to be generated, such as story-writing.
- Encoder-decoder models or sequence-to-sequence models: They are used for tasks where text has to be generated from the input, such as summarization.
Transformer by Google
Release Date: 12th June, 2017
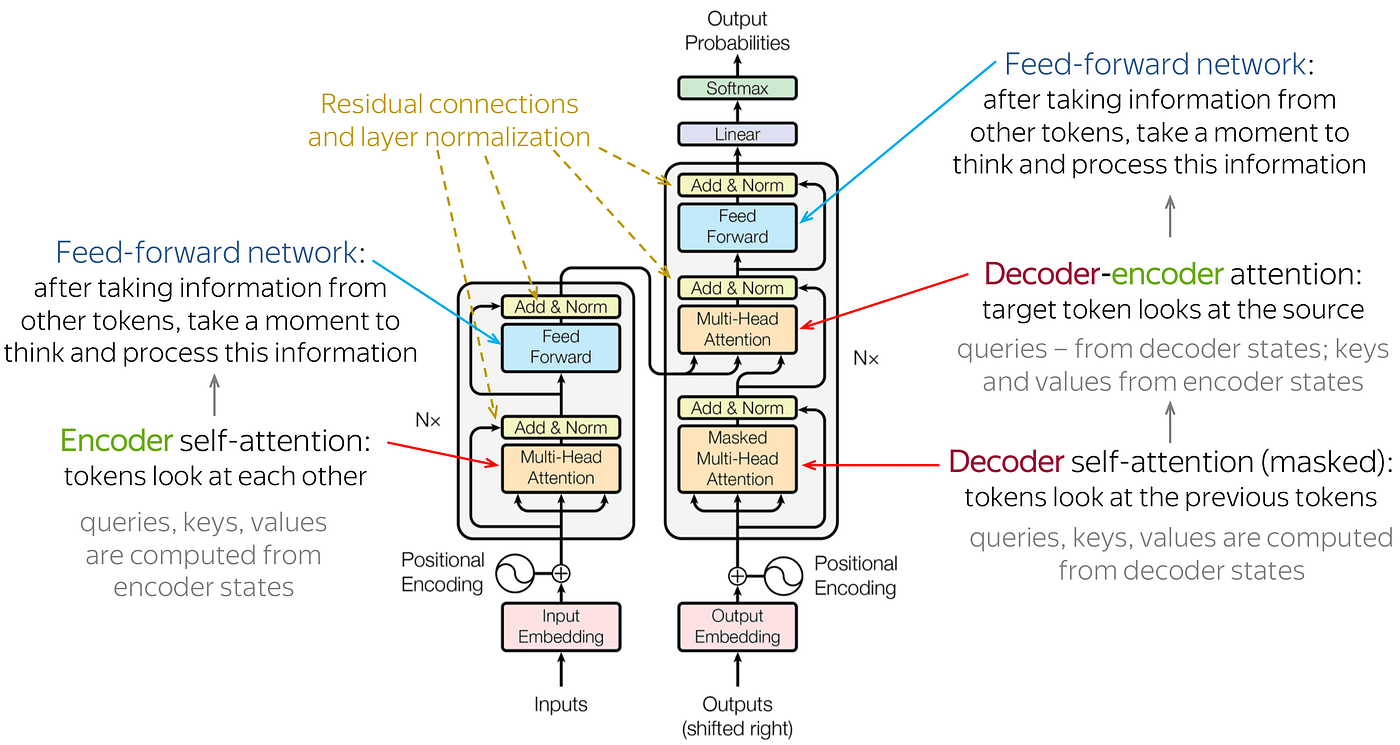
Transformer, a revolutionary model, was introduced in 2017 by Google researchers in the paper “Attention is all you need”. Transformers were primarily made for NLP tasks. They differed from Recurrent Neural Networks in the following ways:
- RNNs take in sequential data. For example, if my input is a sentence, RNNs will take one word at a time as input. This isn’t the case for transformers as they are non-sequential. They can take all the words of the sentence as the input.
- What makes transformers even more special is the attention mechanism. It is the attention mechanism because of which transformers understand the context and can access past information. RNNs can access past information only to a certain extent, mostly only the previous state. The information gets lost in the next states.
- Positional Embeddings: Transformers use this to store information regarding the position of words in a sentence.
These were the reasons why transformers got popular in no time. Transformers had surpassed RNNs in all the NLP tasks. This is why it is important to understand this architecture and its evolution in the past 5 years.
GPT by OpenAI
Release Date: 11th June, 2018
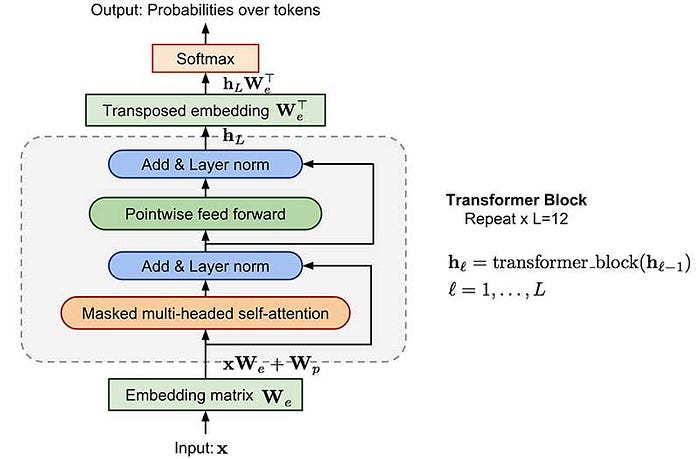
Man, GPT has had its own evolution over in the recent years. There isn’t a better model to begin talking about transformers than GPT. GPT stands for Generative Pre-Training. It introduced the concept of unsupervised learning as pre-training and supervised learning for fine-tuning which is now widely used by many transformers.
It was trained on a book corpus dataset consisting of 7000 unpublished books. The architecture of GPT consists of 12 decoders stacked together, meaning it is a decoder-only model. GPT-1 consists of 117 million parameters, a small number compared to the transformers developed today! It is unidirectional as it consists of decoders. Decoders mask the token to the right of the current token. It generates one token at a time and takes that output as the input for the next timestep. GPT was just the beginning of the era of transformers. What laid ahead was even more fascinating!
BERT by Google
Release Date: 11th October, 2018
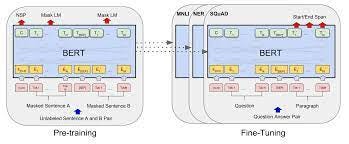
BERT stands for Bidirectional Encoder Representation from Transformers. As the name, suggests, BERT is a bidirectional model. The attention mechanism is able to attend to both the directions of the current token, left as well as right. This is because BERT is made by stacking together 12 encoders, meaning it is an encoder-only model. Encoders can take the full sentence as the input and therefore reference any word of the sentence to perform the task.
BERT consists of 110 million parameters. Like GPT, it was trained on a specific task and can be fine-tuned for other tasks. It was pre-trained in a special way. In simpler words, the task which was used to pre-train BERT was fill in the blanks.
GPT-2 by OpenAI
Release Date: 14th February, 2019
GPT-2, as the name suggests, is the next version of GPT. Like GPT, GPT-2 Large consists of 48 decoders stacked together, making it a decoder-only model. It consists of 1.5 billion parameters. The task on which it was trained was to predict the next word in the sentence given the previous words. It was trained on a dataset of 8 million web pages!
RoBERTa by Facebook
Release Date: 26th July, 2019
RoBERTa stands for Robustly Optimized BERT Pre-Training Approach. The architecture of RoBERTa and BERT is alike. Now you might be wondering, how is it different from BERT? Well, researchers at Facebook optimized the hyperparameters of BERT to achieve State-of-the-art results on the MNLI, QNLI, RTE, STS-B, GLUE and RACE tasks.
It removed BERT’s next-sentence pretraining objective, trained it with much larger mini-batches and learning rates and also changed the masking pattern. It was also trained on more data than BERT. It was trained on existing unannotated NLP datasets as well as CC-News, a novel set drawn from public news articles.
Conclusion
As we saw, the initial approach of many researchers after the release of Transformers was to separate the encoder and decoder architectures and stack them to create a whole new architecture capable of performing certain NLP tasks better than the original Transformer model. Another important aspect that we talked about was the unsupervised learning method for pre-training and then supervised learning for fine-tuning the model.
You can access the final part of the “Evolution of Transformers” series over here!
References
[1] Zuhaib Akhtar, Introduction to GPT Models
[2] Jacob Devlin, Ming-Wei Chang, Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
[3] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, Language Models are Unsupervised Multitask Learners
[4] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov, RoBERTa: A Robustly Optimized BERT Pretraining Approach
